
Workflows
Workflow Workers
Infinitic workers can be configured to orchestrate workflows. The roles of workflow workers are:
- to listen to Pulsar for messages intended for this workflow
- record workflow history in database
- dispatch tasks or sub-workflows based on the workflow definition
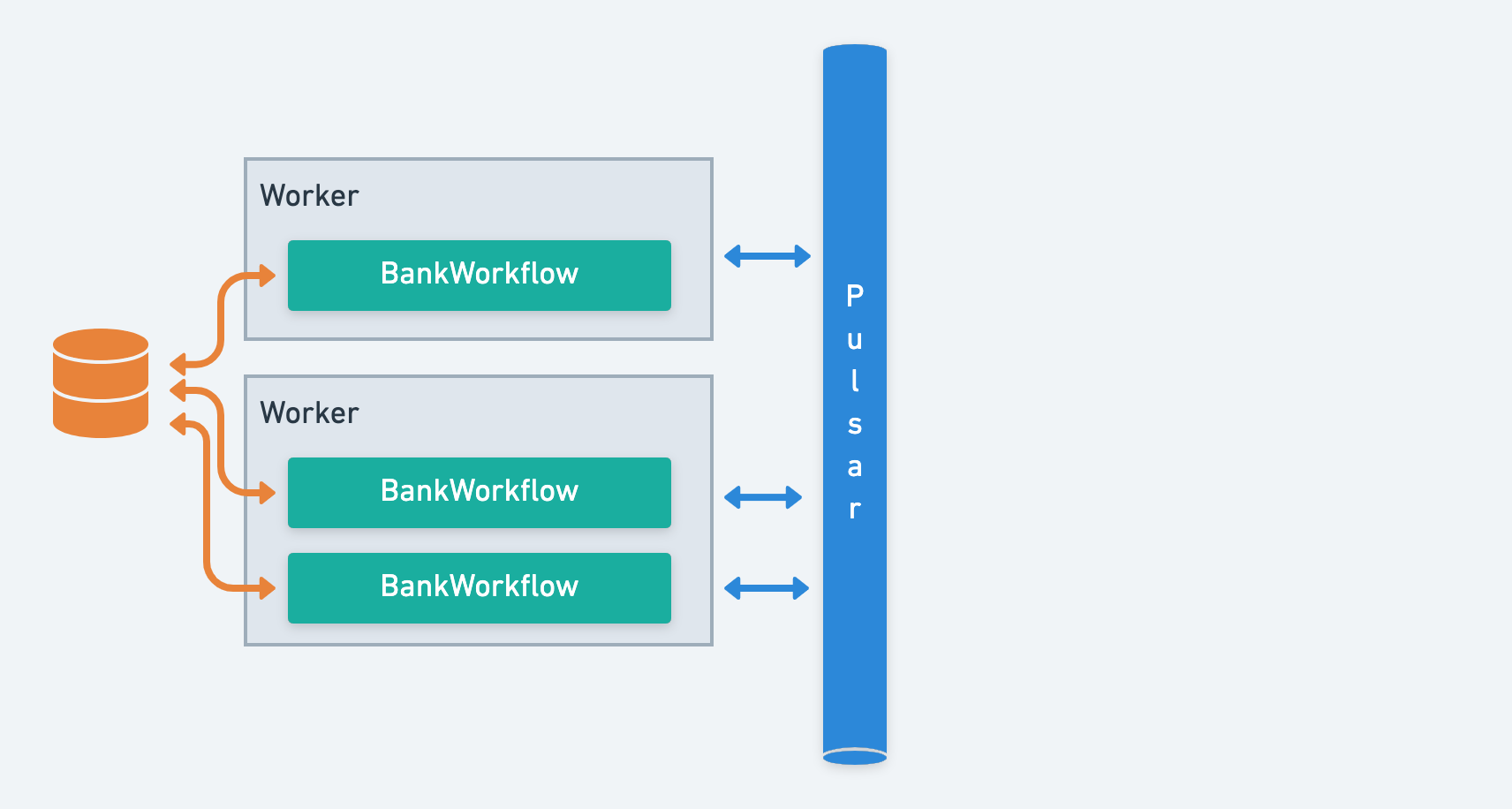
Workflow workers are horizontally scalable: to increase throughput and resilience, just start workers on multiple servers.
Starting a Workflow worker
First, let's add the infinitic-worker dependency into our project:
dependencies {
...
implementation "io.infinitic:infinitic-worker:0.14.1"
...
}
dependencies {
...
implementation("io.infinitic:infinitic-worker:0.14.1")
...
}
Then, we can start a worker with:
import io.infinitic.workers.InfiniticWorker;
public class App {
public static void main(String[] args) {
try(InfiniticWorker worker = InfiniticWorker.fromConfigFile("infinitic.yml")) {
worker.start();
}
}
}
import io.infinitic.workers.InfiniticWorker
fun main() {
InfiniticWorker.fromConfigFile("infinitic.yml").use { worker ->
worker.start()
}
}
We can also use .fromConfigResource("/infinitic.yml") if the configuration file is located in the resource folder.
Configuration file
Here is an example of a valid infinitic.yml file:
# (Optional) worker name
name: optional_worker_name
# How to access the database storing running workflow states
storage:
redis:
host: localhost
port: 6379
user:
password:
database: 0
# How to access Pulsar
pulsar:
brokerServiceUrl: pulsar://localhost:6650
webServiceUrl: http://localhost:8080
tenant: infinitic
namespace: dev
# (Optional) Default settings for the workflows below
workflowDefault:
concurrency: 10
timeoutInSeconds: 400
retry:
maximumRetries: 6
checkMode: strict
# List of workflows that this worker processes
workflows:
- name: example.booking.workflows.BookingWorkflow
class: example.booking.workflows.BookingWorkflowImpl
concurrency: 10
When provided, the worker name must be unique among all workers and clients connected to the same Pulsar namespace.
Workflows
| Name | Type | Description |
|---|---|---|
name | string | name of the workflow (its interface per default) |
class | string | name of the class to instantiate |
concurrency | integer | maximum number of messages processed in parallel |
timeoutInSeconds | double | maximum duration of a workflow task execution before timeout |
retry | RetryPolicy | retry policy for the workflow tasks of this workflow |
checkMode | WorkflowCheckMode | mode used to check if a workflow is modified while still running |
Any class declared in this configuration file must have an empty constructor (to be instantiable by workers).
Concurrency
Per default, workflow instances are executed one after the other for a given workflow. If we provide a value for concurrency, like:
concurrency: 50
the Workflow worker will process at most 50 workflow tasks in parallel for this service.
Whatever the concurrency value, we can have millions of workflows alive. The concurrency value describes how many workflows (at most) this worker moves one step forward at a given time.
Timeout policy
Per default, workflow tasks have a timeout of 60 seconds. Except in the case of a very long history with thousands of tasks and complex (de)/serialization, there is no reason why a workflow task should take so long.
Nevertheless - like for services - it's possible to change this behavior through the timeoutInSeconds parameter, or directly from the Workflow, through a WithTimeout interface or a @Timeout annotation
Retries policy
Per default, the workflow tasks are not retried. Indeed, since workflows' implementation must be deterministic, a retry would result in the same failure.
Nevertheless - like for services - it's possible to change this behavior through the retry parameter, or directly from the Workflow, through a WithRetry interface or a @Retry annotation.
Workflow Check Mode
The checkMode parameter lets us define how Infinitic checks that a workflow was not modified while running.
none: no verification is donesimple: verification that the current workflow execution is the same as the workflow's history, but without checking the values of tasks' parametersstrict: verification that the current workflow execution is the same as the workflow's history
The default value is simple. The check mode can also be defined directly from the Workflow, through a @CheckMode annotation
Storage
Infinitic automaticaly store the current state of running workflows in a database.
If you have running workflows, do not change the storage access configuration. If Infinitic cannot locate the workflow history for an instance, it will assume the instance has terminated, and all related existing messages will be discarded.
Using Redis
Example of a configuration for using Redis for state storage:
storage:
redis:
host: # default: "127.0.0.1"
port: # default: 6379
timeout: # default: 2000
user: # default: null
password: # default: null
database: # default: 0
ssl: # default: false
poolConfig:
maxTotal: # default: -1
maxIdle: # default: 8
minIdle: # default: 0
Redis is not recommended in production, because in case of a crash, last states may not have been saved correctly on disk.
Using MySQL
Example of a configuration for using MySQL for state storage:
storage:
mysql:
host: # default: "127.0.0.1"
port: # default 3306
user: # default "root"
password: # default null
database: # default "infinitic"
keySetTable: # default "key_set_storage"
keyValueTable: # default "key_value_storage"
maximumPoolSize: # HikariConfig default
minimumIdle: # HikariConfig default
idleTimeout: # HikariConfig default
connectionTimeout: # HikariConfig default
maxLifetime: # HikariConfig default
Infinitic utilizes a HikariDataSource with the following HikariConfig properties: maximumPoolSize, minimumIdle, idleTimeout, connectionTimeout, and maxLifetime.
The database will be automatically created if it does not already exist. By default, Infinitic will create two tables: key_set_storage and key_value_storage. You can customize the table names using the settings keySetTable and keyValueTable.
Using PostreSQL
Example of a configuration for using MySQL for state storage:
storage:
postgres:
host: # default: "127.0.0.1"
port: # default 5432
user: # default "postgres"
password: # default null
database: # default "infinitic"
keySetTable: # default "key_set_storage"
keyValueTable: # default "key_value_storage"
maximumPoolSize: # HikariConfig default
minimumIdle: # HikariConfig default
idleTimeout: # HikariConfig default
connectionTimeout: # HikariConfig default
maxLifetime: # HikariConfig default
Infinitic utilizes a HikariDataSource with the following HikariConfig properties: maximumPoolSize, minimumIdle, idleTimeout, connectionTimeout, and maxLifetime.
The database will be automatically created if it does not already exist. By default, Infinitic will create two tables: key_set_storage and key_value_storage. You can customize the table names using the settings keySetTable and keyValueTable.
State compression
By default, the states of workflows are stored as uncompressed Avro binaries.
To compress them and save storage space in exchange for CPU and a little time, we can add a compression option:
storage:
compression: "deflate"
...
The possible options are deflate, gzip, and bzip2, and use the Apache Commons Compress algorithms.
It's possible to add, remove, or change the compression algorithm without causing backward compatibility issues.
Cache
Caffeine cache
Infinitic allows you to use Caffeine as an in-memory cache for storage requests.
Here is an example of configuration:
cache:
caffeine:
maximumSize: 10000
expireAfterAccess: 3600
expireAfterWrite:
No cache
By default, there is no cache. The equivalent configuration is:
cache:
none:
Workflow registration
We can register a service directly with a worker. It can be useful if we need to inject some dependencies in our service:
import io.infinitic.workers.InfiniticWorker;
public class App {
public static void main(String[] args) {
try(InfiniticWorker worker = InfiniticWorker.fromConfigFile("infinitic.yml")) {
worker.registerWorkflowExecutor(
// workflow name
BookingWorkflow.class.getName(),
// workflow implementation class
BookingWorkflowImpl.class,
// number of parallel processings (default: 1)
50,
// instance of WithTimeout (default: null)
withTimeout,
// instance of WithRetry (default: null)
withRetry,
// workflow check mode (default: simple)
WorkflowCheckMode.strict
);
worker.start();
}
}
}
import io.infinitic.workers.InfiniticWorker
fun main(args: Array<String>) {
InfiniticWorker.fromConfigFile("infinitic.yml").use { worker ->
worker.registerWorkflowExecutor(
// workflow name
BookingWorkflow::class.java.name,
// workflow implementation class
BookingWorkflowImpl::class.java
// number of parallel processings (default: 1)
50,
// instance of WithTimeout (default: null)
withTimeout,
// instance of WithRetry (default: null)
withRetry,
// workflow check mode (default: simple)
WorkflowCheckMode.strict
)
worker.start()
}
}
Logging
Exceptions are caught within workflow workers. To view errors, ensure that a Log4J implementation is added to your project.
For example, to use SimpleLogger just add the dependency in our Gradle build file:
dependencies {
...
implementation "org.slf4j:slf4j-simple:2.0.3"
...
}
dependencies {
...
implementation("org.slf4j:slf4j-simple:2.0.3")
...
}
and this simplelogger.properties example file in our resources directory:
# SLF4J's SimpleLogger configuration file
# Simple implementation of Logger that sends all enabled log messages, for all defined loggers, to System.err.
# Uncomment this line to use a log file
#org.slf4j.simpleLogger.logFile=infinitic.log
# Default logging detail level for all instances of SimpleLogger.
# Must be one of ("trace", "debug", "info", "warn", or "error").
# If not specified, defaults to "info".
org.slf4j.simpleLogger.defaultLogLevel=warn
# Set to true if you want the current date and time to be included in output messages.
# Default is false, and will output the number of milliseconds elapsed since startup.
org.slf4j.simpleLogger.showDateTime=true
# Set to true if you want to output the current thread name.
# Defaults to true.
org.slf4j.simpleLogger.showThreadName=false
# Set to true if you want the last component of the name to be included in output messages.
# Defaults to false.
org.slf4j.simpleLogger.showShortLogName=true