
References
Batching
Batch processing, introduced in Infinitic 0.16.2, is a powerful performance optimization feature that allows multiple messages to be processed together in batches rather than individually. This capability can improve throughput by up to 10x in high-volume scenarios.
By reducing the number of network calls and database operations required, batching significantly improves performance for both Infinitic's internal operations (like database updates) and user-defined tasks (like bulk API calls). This page explains how batching works in Infinitic and how to leverage it effectively in your applications.
Understanding Batch Processing in Infinitic
Here is what happens when the batching feature is set for an Infinitic component
Message Consumption
When an Infinitic component receives messages from the message broker, it can consume multiple messages at once in a single batch. This batching at the consumption level reduces the number of network calls needed to retrieve messages. For example, instead of making 1000 individual network calls to consume 1000 messages, the component can retrieve all 1000 messages in a single network call. This significantly reduces latency and network overhead, especially when processing high volumes of messages.
Messages Processing
Then, messages are processed in batches, providing benefits both internally for Infinitic components and for user-defined tasks:
- Infinitic internal components that interact with databases (Workflow State Engine, Workflow Tag Engine, and Service Tag Engine) group multiple database operations into a single transaction.
- User-defined tasks are grouped and processed together
Message processing include message sending. Here also multiple messages are grouped into a single batch. This reduces the number of network calls needed to publish messages. For example, instead of making 1000 individual network calls to publish 1000 messages, the component can send all 1000 messages in a single network call.
Messages Acknowledgment
Similarly to message consumption and publishing, message acknowledgments (or negative acknowledgments) are also batched. Instead of sending individual acknowledgments for each processed message, multiple acknowledgments are grouped and sent together to the message broker. This reduces the number of network calls needed to acknowledge messages, further improving performance and reducing network overhead. For example, if 1000 messages have been processed successfully, a single batch acknowledgment can be sent instead of 1000 individual acknowledgments.
Service and Workflow Executors
Without batching, messages are processed individually and in parallel based on the concurrency setting. Each message goes through three sequential phases:
- Deserialization - The message is deserialized from its transport format
- Processing - The actual business logic is executed
- Acknowledgment - The message broker is notified of successful processing
These phases happen independently for each message, as shown in the diagram below:
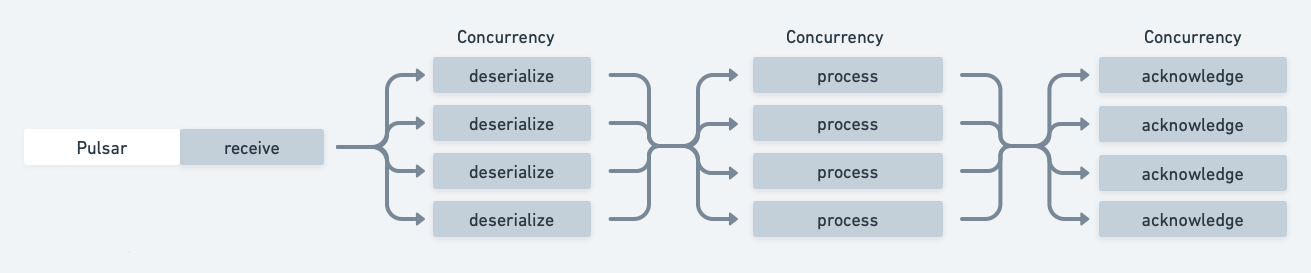
With batching, messages are processed in batches and in parallel. Messages are received into batches based on the batch.maxMessages setting (e.g. 1000 messages per batch). These batches are then processed in parallel according to the concurrency setting (e.g. 10 concurrent batches). For example, with concurrency = 10 and batch.maxMessages = 1000, the system can process up to 10,000 messages simultaneously in memory
For Service Executors specifically, messages within each batch can be further re-grouped using a custom batchKey. This allows related messages to be processed together efficiently, as shown in the diagram below:

Workflow State and Workflow Tag Engines
The Workflow State Engine and Workflow Tag Engine require special handling to maintain data consistency:
- The Workflow State Engine must process messages for a given workflow instance sequentially to maintain workflow state integrity. For example, if workflow A has two pending messages, they must be processed one after another, not simultaneously.
- Similarly, the Workflow Tag Engine must process messages for a given workflow tag sequentially, to avoid race conditions.
Without batching, messages are first sharded by their key (workflow ID for State Engine, workflow tag for Tag Engine) to ensure sequential processing within each key. Then messages are processed individually and in parallel based on the concurrency setting, but messages with the same key are never processed simultaneously. This is illustrated in the diagram below:

With batching, messages are first collected into batches based on the batch.maxMessages setting (e.g. 1000 messages per batch). These batches are then sharded by their key (workflow ID for State Engine, workflow tag for Tag Engine) to group related messages together. The resulting key-based batches are processed in parallel according to the concurrency setting, while ensuring sequential processing within each key.
This approach optimizes throughput while maintaining data consistency by:
- Processing multiple independent keys in parallel
- Batching related messages with the same key together
- Preserving sequential processing order within each key
- Minimizing database transactions through batch processing (only one read and one write by batch)

Performance Benefits
The introduction of batch processing in Infinitic yields several significant performance improvements:
- Reduced Network Latency: By consolidating multiple operations into single network calls, the overall latency is dramatically reduced. For example, processing 1000 tasks can be done with a single network round-trip instead of 1000 individual calls.
- Lower System Overhead: Minimized database connections and transactions
Real-World Performance Impact
While Infinitic has not yet undergone formal third-party benchmarking, internal testing has shown remarkable improvements:
Local Testing Results:
- Up to 10x throughput improvement for individual components with batching enabled
- Most significant gains seen in scenarios with high message volumes
- Consistent performance improvements across different types of operations
Scale Benefits:
- The performance benefits become even more pronounced at larger scales
- Particularly noticeable when dealing with high-concurrency workloads
- Significant reduction in database contention through optimized access patterns
- Better resource utilization across the entire system
These improvements make Infinitic particularly well-suited for high-throughput production environments where performance and efficiency are critical (thousands of workflows per seconds)